Zero To Prod In C - Creating Server & Hosting
Table of Contents
Background
I recently started looking into self-hosting, and after spending two almost sleepless nights, I finally have a solution to self host any service and link it to an endpoint with your domain name. Usually, you’d need a static IP address that you must purchase from your ISP, and it’s quite costly (depending on bandwith and IP range). This solution does not need any static IP address, or port forwarding or any magic from your side. You just need a machine where you can just do things. In my case I have a Raspberry Pi, on which I’ve installed Ubuntu Server, but this can be any machine that you can keep up for extended periods of time, be it your laptop, or a real home lab setup, everything goes.
Now at first, I thought of writing only about the self-hosting part, but later on, something changed my mind to also include a new thing I’ve worked on recently : My own custom http server implementation in C, that works! So, consider this a bonus on the self-hosting solution. Why in C? It’s the language I know the best and prefer using, and also because I needed something that compiles super fast, and a custom blogging solution of my own. This blog is hosted using the static site generator Hugo and on GitHub Pages, because
- for the moment, this sever is not that well developed,
- My internet connection can be out anytime (not very reliable),
- internet connection is slow, so it takes a bit longer for pages to load, although it’s not noticeable,
- and because now, after exploring self-hosting, I think it’s best to use a static site generator for a blog.
Other than that I think I’ll be implementing some kind of API to make some of the things easier on my local network, maybe something like a self-hosted cloud storage, but for local network only! Now also, one thing to note, I’ve implemented some utility methods to make my task easier. This was not implemented in a single day, and evolved out of my needs. I won’t be providing code for that because if you’re going to implement it, you’re going to do things your way, and also this makes the blog a bit shorter 😄
Now, also, the image shown above displays a very basic server, but when implementing my Http server, I actually implemented web pages in C only, without any external C code, and I also hosted the source code of the server for a few days. Hosting the complete server code was also very easy, I just read complete source code files, and then wrapped those in html code. For styling I took help from ChatGPT and it turned out to be a fine looking website, and I would’ve kept it if not for constantly breaking it when updating the code, and the website going down again and again, whenever that happened.
Who needs a web framework when you can do that all in C and have fun at the same time :-)
— Siddharth Mishra (@brightprogramer) November 21, 2024
Testing out an idea of how web pages will be rendered in components.
Options :
- Use a template engine to replace template code blogs and generate html
- What you see in this picture below pic.twitter.com/8h1Mk066LZ
Socket & Bind
Our clients (web browsers, or command line tools like cURL) will be sending HTTP requests to our server, so for
that we need a socket, bound to a specific port (I’ll use 1337, because I am), and then we’ll have to wait for
incoming connections on it (do a listen() and accept() in a while loop basically)
Creating A Socket
int main() {
// create main socket that the server listens on
int sockfd = socket(AF_INET6, SOCK_STREAM, 0);
if(-1 == sockfd) {
LOG_ERROR("socket() : %s", strerror(errno));
return EXIT_FAILURE;
}
return EXIT_SUCCESS;
}
Very easy, no rocket science. Just call socket(), with AF_INET6 meaning we’ll be usign IPV6 for interacting
with any connections, and SOCK_STREAM means we’ll be using the TCP protocol. Go read about the TCP protocol
first if you don’t know about it, that’ll be slightly helpful in understanding one of the upcoming sections.
The socket() call returns a positive number on success, and -1 on failure. The returned integer represents
a file descriptor, just like
- 0 for
stdin, - 1 for
stdout, and - 2 for
stderr(I might be wrong in that order, but who cares?)
It’s quite possible that the returned value is 4, but we’re not here to make guesses, just take that value, and make sure to check the return value ALWAYS! That instantly saves you from having to debug that thing if something fails!
Binding Socket To An Address & Port
There are 1 - (2^16-1) possible ports on your machine, pick any one! Done? Ok! Now, we’ll be listening on localhost at the port «insert your answer here». You can use a custom address as well, but at this moment, I don’t know much about how that address will be decided. Placing that address in the following code is quite easy and I’m sure you can figure it out.
int main() {
// socket()
// bind socket to an addres
struct sockaddr_in6 server_addr = {0};
server_addr.sin6_family = AF_INET6;
server_addr.sin6_addr = in6addr_any;
server_addr.sin6_port = htons(1337);
int res = bind(sockfd, (struct sockaddr *)&server_addr, sizeof(server_addr));
if(-1 == res) {
LOG_ERROR("bind() failed : %s", strerror(errno));
close(sockfd);
return EXIT_FAILURE;
}
return EXIT_SUCCESS;
}
I’m using port 1337, but you, you don’t copy me, ok? ok.
Getting Connections
Wooh, that’s done, now we need to get our ears out and listen() for incoming connections.
int main() {
// socket()
// bind()
// listen for incoming connections on the socket
res = listen(sockfd, 10); // 10 is the queue size here
if(-1 == res) {
LOG_ERROR("listen() failed : %s", strerror(errno));
close(sockfd);
return EXIT_FAILURE;
}
printf("listening on port %d...\n", port);
return EXIT_SUCCESS;
}
And then accept() incoming connections in a while loop. This will allow us to handle multiple
incoming requests one after another, or concurrently (if creating a multi-threaded server).
int main() {
// socket()
// bind()
// listen()
// will be used to receive requests from connected clients
// and store temporarily before processing
String received_buf = {0};
StringInit(&received_buf);
StringReserve(&received_buf, 1);
// I do have incoming requests and response-ibilities, you know!
// I'll show you these later, don't worry, just understand what I'm doing so you
// get the bigger picture later on
HttpRequest request = {0};
HttpResponse response = {0};
// while there is truth, we must accept!, ah, me and my lame sense of humor XD
while(true) {
struct sockaddr_storage client_addr = {0};
socklen_t addrlen = sizeof(client_addr);
int connfd = accept(sockfd, (struct sockaddr *)&client_addr, &addrlen);
if(-1 == connfd) {
LOG_ERROR("listen() failed : %s", strerror(errno));
close(sockfd);
StringDeinit(&received_buf);
return EXIT_FAILURE;
}
close(connfd); // close after use
}
close(sockfd);
StringDeinit(&received_buf);
HttpResponseDeinit(&response);
HttpRequestDeinit(&request);
return EXIT_FAILURE;
}
Note how I reserve only 1 byte for string. Curious why? Well, I might tell you something that very few posts out there will.
Getting Data From Clients
Below is the complete code I use to receive data from incoming connections.
int main() {
// socket()
// bind()
// listen()
while(true) {
// accept()
// keep getting messages from the stream
ssize_t recv_size = recv(
connfd,
received_buf.data + received_buf.length,
received_buf.capacity - received_buf.length,
MSG_DONTWAIT // non-blocking
);
// try receiving again with a non-blocking call to check whether more data is there to be read or not.
while((-1 != recv_size) && ((EAGAIN != errno) || (EWOULDBLOCK != errno))) {
if(recv_size > 0) {
// keep appending more read data
// because TCP is a stream of data! not a set of packets like UDP.
received_buf.length += recv_size;
// resize if we reached capacity
if(received_buf.capacity == received_buf.length) {
// keep a max limit, otherwise anyone can DOS you out.
if(received_buf.capacity >= 1024 * 1024 * 10) {
StringClear(&received_buf);
__server_send_json_response(
HTTP_RESPONSE_CODE_PAYLOAD_TOO_LARGE,
"{\"error\":\"Request body too large, max limit is 10 MB\"}"
) close(connfd);
continue;
}
StringReserve(&received_buf, received_buf.capacity * 2);
}
} else {
break;
}
// and recv more to see whether more data is left
recv_size = recv(
connfd,
received_buf.data + received_buf.length,
received_buf.capacity - received_buf.length,
MSG_DONTWAIT
);
}
// if there was an error in receiving buffer, and it was not because there was more data left
if((-1 == recv_size) && ((EAGAIN != errno) || (EWOULDBLOCK != errno))) {
LOG_ERROR("recv() failed : %s", strerror(errno));
StringClear(&received_buf);
close(connfd);
continue;
}
LOG_INFO("REQUEST :\%s", received_buf.data);
// close()
}
return EXIT_FAILURE;
}
After reading the above code, you might want to take a look at manpage of recv(),
especially check what are the possible return values. Now, the way I receive data, I’m not making any guess work about the size
of data. Instead of using a growing buffer like me, you can use a static sized buffer of say 10MB, and that’d be way shorter
than this, probably best based on what you want to do. In my case, I wanted to experiment about how we can use a growing
buffer to receive the stream of data from the network buffer present in kernel. Just don’t do one thing, don’t use a small
buffer because it’s possible that you read only part of the request, and hence fail to respond correctly, or atleast,
if you do, then send a response like I do about the payload being too large.
Now, it’s possible to use a growing buffer here because of the MSG_DONTWAIT flag in recv(). It asks the recv() to
not wait for more incoming data and just return -1 with an errno value set. Know that before implementing it this way,
I used a buffer size of 65KB, assuming no requests will be greater than that size, and it’s quite true, max I’ve seen
in the logs generated was less than 1KB (1024).
Responding To Requests
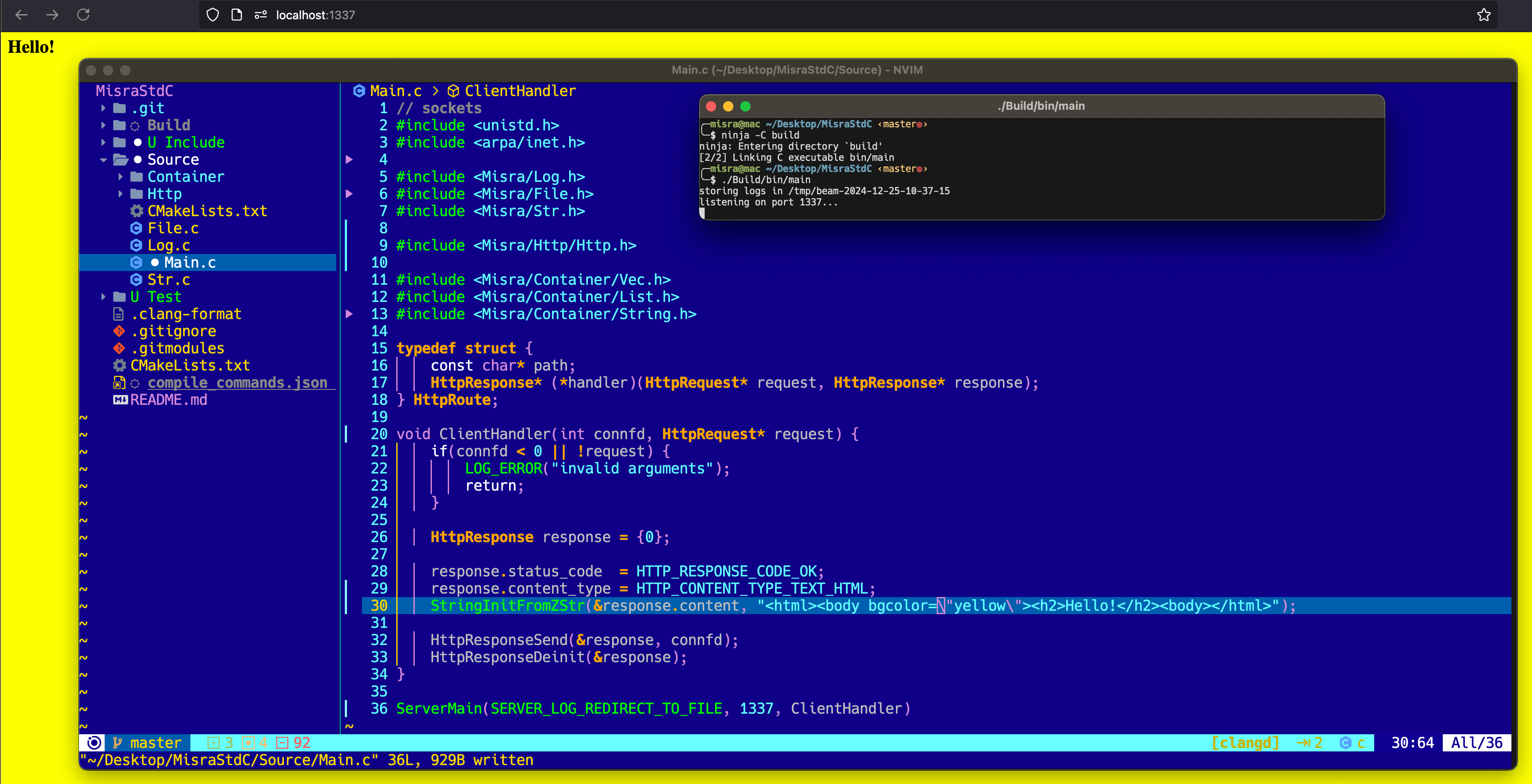
Now, if you’re at the very beginning of writing your server, you probably won’t have any HTTP request parsing code, so you don’t really know what the client asked you to do. It’s best that you just return a static response, like the html response in the very first image of this blog post, and then build things from there. I’ll just show you how mine looks after doing it all!
int main() {
// socket()
// bind()
// listen()
while(true) {
// accept()
// recv()
// Parse http request
size_t rem_size = received_buf.length;
if(!HttpRequestParse(&request, received_buf.data, &rem_size)) {
LOG_ERROR("failed to parse http request");
LOG_ERROR("request was :\n%s", received_buf.data);
__server_send_json_response(
HTTP_RESPONSE_CODE_BAD_REQUEST,
"{\"error\":"Bad Request.\"}"
);
continue;
}
/* process request and send a response */
if(ClientHandler(&response, &request, connfd)) {
HttpResponseSend(&response, connfd);
} else {
__server_send_json_response(
HTTP_RESPONSE_CODE_INTERNAL_SERVER_ERROR,
"\"error\":\"Failed to handle client request.\""
);
}
HttpRequestReset(&request); // reset for reuse
HttpResponseReset(&response); // reset for reuse
StringClear(&received_buf); // reset for reuse
// close()
}
return EXIT_FAILURE;
}
and my client handler is a simple method that just returns without even checking the http request.
HttpResponse* ClientHandler(HttpResponse* response, HttpRequest* request, int connfd) {
if(connfd < 0 || !request || !response) {
LOG_ERROR("invalid arguments");
return NULL;
}
response->status_code = HTTP_RESPONSE_CODE_OK;
response->content_type = HTTP_CONTENT_TYPE_TEXT_HTML;
StringPrintf(
&response->content,
"<html><body bgcolor=\"yellow\"><h2>Hello!</h2><body></html>"
);
return response;
}
In my case, I wrapped the whole main function in a macro to be able to create a server in just any source file, and that’s what you see in the very first image.
HTTP
Now to begin parsing http requests, you need to get familiar with RFC-2616
which describes how HTTP/1.1 protocol works. Get to know how a general HTTP/1.1 request looks like. I took help
from ChatGPT to provide me with examples of HTTP requests. Once I understood the general format, parsing was easy,
with many debugging sessions obviously.
Parsing Requests
The very first line of a HTTP/1.1 request contains the following information.
METHOD URL VERSION
I defined three different functions to help me parse each one of these.
///
/// Try to parse first few characters of given raw string
///
/// method[out] : Parsed http method will be stored here.
/// raw_request_str[in] : Raw request string recevied from client through a recv call.
/// remaining_size[in,out] : Provides an idea of remaining size of `raw_request_str` buffer,
/// and returns the remaining size of buffer after parsing is complete.
/// If parsing fails, this is left unchanged.
///
/// SUCCESS : Returns pointer after which parsing must continue.
/// remaining_size variable is updated with new remaining size.
/// FAILURE : Returns NULL. remaining_size variable is not altered.
///
static const char *http_request_method_parse(
HttpRequestMethod *method,
const char *raw_request_str,
size_t *remaining_size
);
///
/// Parse and get HTTP url from raw request string.
///
/// url[out] : Where pointer to url string will be stored. The created string
/// is created using strdup() and hence must be destroyed after use.
/// raw_request_str[in] : Position to start parsing from.
/// remaining_size[in,out] : Remaining size in raw_request_str.
///
/// SUCCESS : Position to continue parsing from
/// remaining_size variable is updated with new remaining size.
/// FAILURE : NULL. remaining_size variable is not altered.
///
static const char *http_url_parse(String *url, const char *raw_request_str, size_t *remaining_size);
///
/// Check whether the http request version matches that supported by this server.
///
/// NOTE: for now we recognize only HTTP/1.1
///
/// raw_request_str[in] : Position to start parsing from.
/// remaining_size[in,out] : Remaining size in raw_request_str.
///
/// SUCCESS : Position to continue parsing from
/// remaining_size variable is updated with new remaining size.
/// FAILURE : NULL. remaining_size variable is not altered.
///
static const char *http_version_validate(const char *raw_request_str, size_t *remaining_size);
Each take a first arguemnt as pointer to what they should parse and store. Rest argumens are
raw_request_str: This is where the corresponding helper function will begin parsing fromremaining_size: This is the number of bytes that’s left inraw_request_strand that’s the max bytes we must read. Reading beyond that is UB.
After parsing is done, and if parsing is successful, then the method will store the parsed result in first argument,
and then return pointer to where the next parser method will continue parsing from, meaning the updated raw_request_str.
As an example, I’ll show you how I implemented the method to parse the HTTP method.
const char *http_request_method_parse(
HttpRequestMethod *method,
const char *raw_request_str,
size_t *remaining_size
) {
if(!method || !raw_request_str || !remaining_size) {
LOG_ERROR("invalid arguments");
return NULL;
}
size_t rem_size = *remaining_size;
if(!rem_size) {
LOG_ERROR("unsufficient size to parse http method");
return NULL;
}
const char *line_end = memchr(raw_request_str, '\r', rem_size);
if(!line_end || '\n' != line_end[1]) {
LOG_ERROR("failed to get first line of http request.");
}
// method name and request url are separated by a space
const char *method_end = memchr(raw_request_str, ' ', rem_size);
if(!method_end) {
LOG_ERROR("invalid http request method.");
return NULL;
}
if(method_end >= line_end) {
LOG_ERROR("malformed http request, method end exceeds line end");
return NULL;
}
// compute method size
size_t method_size = method_end - raw_request_str;
if(!method_size) {
LOG_ERROR("invalid http request method.");
return NULL;
}
// compare based on method_size for faster search
if(method_size == 7) {
if(0 == strncmp(raw_request_str, "OPTIONS", 7)) {
raw_request_str += 8;
rem_size -= 8;
*method = HTTP_REQUEST_METHOD_OPTIONS;
} else if(0 == strncmp(raw_request_str, "CONNECT", 7)) {
raw_request_str += 8;
rem_size -= 8;
*method = HTTP_REQUEST_METHOD_CONNECT;
} else {
*method = HTTP_REQUEST_METHOD_UNKNOWN;
}
} else if(method_size == 6) {
if(0 == strncmp(raw_request_str, "DELETE", 6)) {
raw_request_str += 7;
rem_size -= 7;
*method = HTTP_REQUEST_METHOD_DELETE;
} else {
*method = HTTP_REQUEST_METHOD_UNKNOWN;
}
} else if(method_size == 5) {
if(0 == strncmp(raw_request_str, "PATCH", 5)) {
raw_request_str += 7;
rem_size -= 7;
*method = HTTP_REQUEST_METHOD_PATCH;
} else if(0 == strncmp(raw_request_str, "TRACE", 5)) {
raw_request_str += 7;
rem_size -= 7;
*method = HTTP_REQUEST_METHOD_TRACE;
} else {
*method = HTTP_REQUEST_METHOD_UNKNOWN;
}
} else if(method_size == 4) {
if(0 == strncmp(raw_request_str, "POST", 4)) {
raw_request_str += 5;
rem_size -= 5;
*method = HTTP_REQUEST_METHOD_POST;
} else {
*method = HTTP_REQUEST_METHOD_UNKNOWN;
}
} else if(method_size == 3) {
if(0 == strncmp(raw_request_str, "GET", 3)) {
raw_request_str += 4;
rem_size -= 4;
*method = HTTP_REQUEST_METHOD_GET;
} else if(0 == strncmp(raw_request_str, "PUT", 3)) {
raw_request_str += 4;
rem_size -= 4;
*method = HTTP_REQUEST_METHOD_PUT;
} else {
*method = HTTP_REQUEST_METHOD_UNKNOWN;
}
} else {
*method = HTTP_REQUEST_METHOD_UNKNOWN;
}
*remaining_size = rem_size;
return raw_request_str;
}
Rest methods you must figure out yourselves. You’d next need to parse :
- The request url, for eg: if the complete url is
https://brightprogrammer.in/docs, then this will contain only/docsas URL. - Check the version number if you want, I do! But, it’s your choice.
- Parse headers
- Find
Content-TypeandContent-Lengthheaders if you want to parse the request body as well. The string comparision must be case-insensitive.
For the string comparision in finding the headers, I had to define my own method to do string comparision, because it turns out there’s no standard method in C to do this. This part depends on platform, and I don’t want my code to be dependent on a single platform too much, it must be able to run anywhere with minimal modifications
String Compare
// stdlib
#include <ctype.h>
// In Str.h
typedef enum {
STR_CMP_IGNORE_CASE = 0,
STR_CMP_WITH_CASE = 1,
} StrCmpCase;
///
/// Compare two strings with case sensitivity
///
/// a[in] : First string
/// b[in] : Second string
/// case_sensitive[in] : If true then string comparision will be case-sensitive.
/// If false then string comparision will NOT be case-sensitive.
///
/// return : True if strings are equal
/// return : False otherwise
///
bool StrCompare(const char* a, const char* b, StrCmpCase case_sensitive);
// In Str.c
bool StrCompare(const char* a, const char* b, StrCmpCase case_sensitive) {
if(!a || !b) {
LOG_ERROR("invalid arguments.");
return false;
}
// do a case-insensitive match
while(*a && *b) {
int d = case_sensitive == STR_CMP_WITH_CASE ?
(*a - *b) :
(tolower((unsigned char)*a) - tolower((unsigned char)*b));
if(d != 0) {
return false;
}
a++;
b++;
}
if(*a || *b) {
return false;
}
return true;
}
Handling Requests
Now to handle requests, you already know the request method, you have the content and it’s body, and every header is already parsed, you just need to decide what endpoint it is and handle the request based on that. Cool! This means I can get to the routing part.
Oh, and btw, this is how my HttpRequest and HttpResponse structures look like :
typedef struct {
HttpRequestMethod method;
String url;
HttpHeaders headers;
HttpContentType content_type;
String content;
} HttpRequest;
typedef struct {
HttpResponseCode status_code; ///< Http status code to be sent.
HttpHeaders headers; ///< All HTTP headers to be sent during a repsonse.
String body; ///< Final response is generated and stored here before sending.
HttpContentType content_type; ///< Type of data in http content.
String content; ///< Content to be sent is stored here temporarily.
} HttpResponse;
Routing
Routing is very easy to implement, and you don’t need a complex structure for that, you’ll only need
- an endpoint string,
- and a handler for that endpoint,
like this :
typedef struct {
const char* path;
HttpResponse* (*handler)(HttpRequest* request, HttpResponse* response);
} HttpRoute;
The handler will return NULL if something bad happens, otherwise it’ll return the
provided response object as parameter. And, now for routing, we only need an array
of this structure that maps an endpoint to it’s corresponding handler. This way
you can also create a router for different hosts (provided in http header as Host:).
So for eg:
- I hosted the source code of my server at
code.brightprogrammer.in, - and the blog was hosted at
brightprogrammer.in
So, now with a router, your server code will look like this
HttpResponse* UploadFileHandler(HttpRequest* request, HttpResponse* response) {
if(!request || !response) {
LOG_ERROR("invalid arguments");
return NULL;
}
// get the uploaded file in http request
return response;
}
HttpResponse* GetFileHandler(HttpRequest* request, HttpResponse* response) {
if(!request || !response) {
LOG_ERROR("invalid arguments");
return NULL;
}
// send a file to client based on request
return response;
}
HttpResponse* ClientHandler(HttpResponse* response, HttpRequest* request, int connfd) {
if(connfd < 0 || !request || !response) {
LOG_ERROR("invalid arguments");
return NULL;
}
HttpRoute route[] = {
{ .path = "/upload", UploadFileHandler},
{.path = "/get_file", GetFileHandler}
};
size_t num_routes = sizeof(route) / sizeof(route[0]);
for(size_t r = 0; r < num_routes; r++) {
if(StrCompare(route[r].path, request->url.data, STR_CMP_IGNORE_CASE)) {
return route[r].handler(request, response);
}
}
// default response
response->status_code = HTTP_RESPONSE_CODE_OK;
response->content_type = HTTP_CONTENT_TYPE_TEXT_HTML;
StringInitFromZStr(
&response->content,
"<html><body bgcolor=\"yellow\"><h2>Hello!</h2><body></html>"
);
return response;
}
Now, you have a fully up and running http server that can both act as serving your blog or as a web app as a REST API backend, or anything you want it to be.
Generating Dynamic HTML
For generating HTML on the fly I used this
typedef List(String) Html;
You can load HTML from a static file, or generate it at runtime. You can parse the loaded static HTML file, and replace parts of it, to again make it dynamic, and maybe even build your own templating engine.
My whole website frontend was made from these methods :
// kepp wrapping to make a song
Html *HtmlWrap(Html *html, const char *before_zstr, const char *after_zstr) {
if(!html || !before_zstr || !after_zstr) {
LOG_ERROR("inalid arguments");
return NULL;
}
String data[2];
TempStringFromZStr(data, before_zstr);
TempStringFromZStr(data + 1, after_zstr);
ListPushFront(html, data);
ListPushBack(html, data + 1);
memset(data, 0, sizeof(data));
return html;
}
Html* WrapFileContent(Html* html, const char* filepath);
Html* Wrap404(Html* html);
Html* WrapDirEntryInTable(Html* html, DirEntry* entry);
Html* WrapDirContents(Html* html, DirContents* dir_contents);
Html* WrapContent(Html* html);
Html* WrapBase(Html* html);
As an example here are few of the functions, using HtmlWrap()
Html* WrapContent(Html* html) {
if(!html) {
LOG_ERROR("invalid arguments.");
return NULL;
}
if(!HtmlWrap(html, "<center>", "</center>")) {
LOG_ERROR("failed to wrap html.");
return NULL;
}
return html;
}
Html* WrapDirEntryInTable(Html* html, DirEntry* entry) {
if(!html || !entry) {
LOG_ERROR("invalid arguments.");
return NULL;
}
HtmlAppendFmt(
html,
"<tr>"
"<th><a href=\"%s/\">%s</a></th>"
"<th>%s</th>"
"</tr>",
entry->name.data,
entry->name.data,
DirEntryTypeToZStr(entry->type)
);
return html;
}
Html* WrapDirContents(Html* html, DirContents* dir_contents) {
if(!html || !dir_contents) {
LOG_ERROR("invalid arguments.");
return NULL;
}
HtmlAppendFmt(
html,
"<tr>"
"<th>Name</th>"
"<th>Type</th>"
"</tr>"
);
DirEntry* entry = NULL;
size_t i = 0;
VecForeachPtr(dir_contents, entry, i) {
WrapDirEntryInTable(html, entry);
}
HtmlWrap(html, "<table>", "</table>");
return html;
}
And, now maybe you get the idea… This is how it all looked, just to give an impression that it’s really possible to build an entire web app in C, both frontend AND backend, without using complex libraries. And, if you add some WASM support, you can build something like leptos-rs for C.
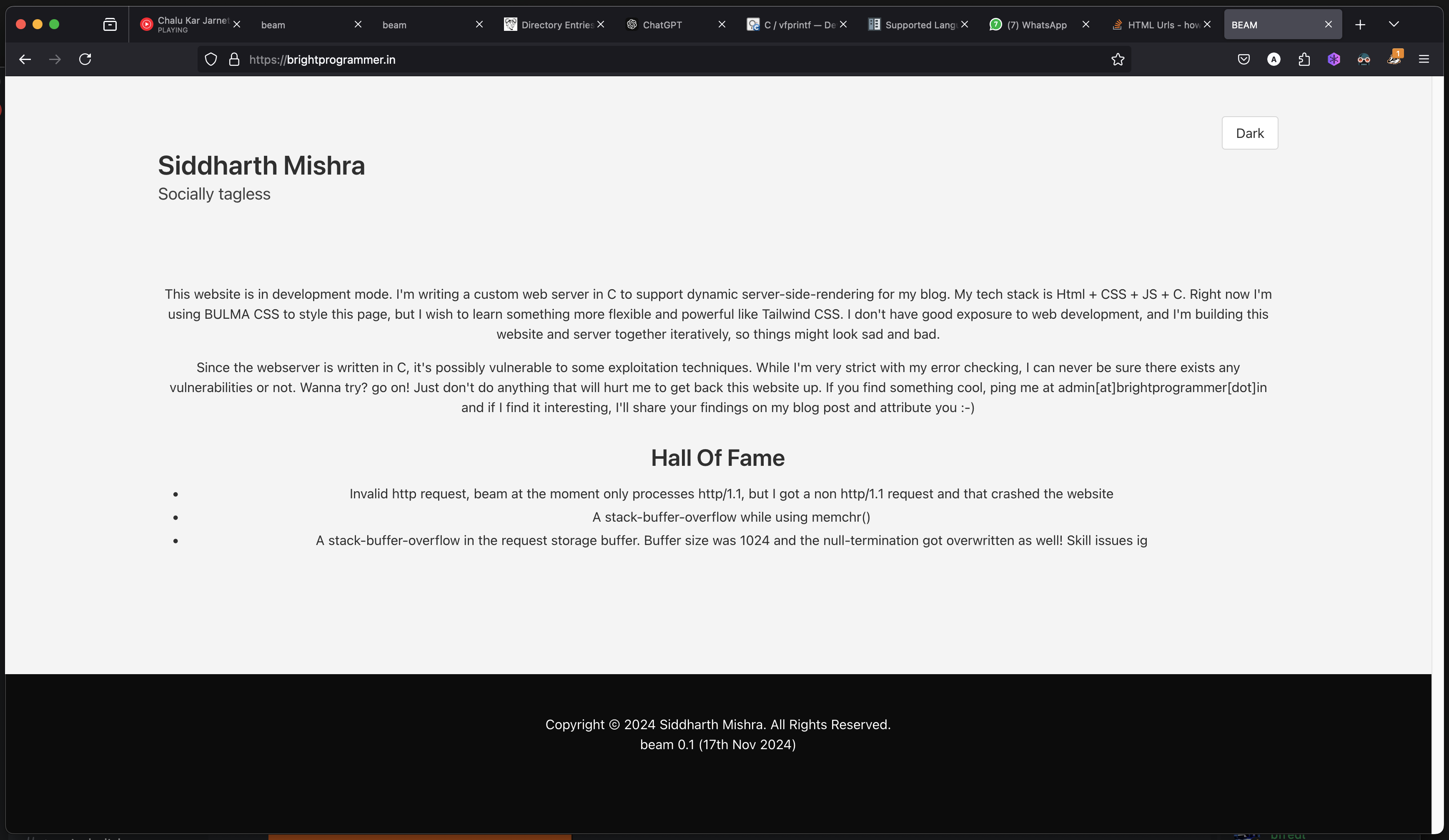
Hosting
Hosting is very very easy.
- Get a machine where you’ll host your service
- Get a domain name
- Change your DNS provider to cloudflare if not done already
- The last step obviously requires you to setup a cloudflare account.
- Then create a cloudflare tunnel
- For this you need to create an account at ZeroTrust
- Create a tunnel, do the installation, it’s very easy
- Setup the public hostnames
After doing all this, start your server, and then in the public hostnames part set that port
and localhost at HTTP. The HTTP part can be changed depending on whether you’re behind a proxy
that already handles HTTPS for you or not (like nginx). When using tunnel, you don’t really
need to handle HTTPS yourself, because cloudflare automatically does that for you. Just play
around with your cloudflare dashboard and you’ll get to know a lot.
With this method, you don’t need any port-forwarding, or using dynamic-dns (DDNS), or purchase
a static IP. ZeroTrust will automatically add DNS entries for whatever public hostnames you
create in your tunnel. The way this works is that cloudflare takes client requests on your behalf,
reads those requests, parses and converts those requests and then forwards it to the tunnel,
the tunnel then receives those requests and forwards it to the final service at the address and
port you specified. In my case it’ll be something like https://localhost:1337
All of this is just your friendly-neighbourhood ssh port-forwarding. You don’t really need to
use cloudflare if you have access to a system that either has a DDNS setup or has a static IP,
because you can then use ssh port-forwarding to do all this for you. I don’t know about HTTPS
in that case, but that can be easily handled by using a proxy manager like nginx.
Comments
While all this is done, I did face some problems while using cloudflare tunnel. It somehow
removes the request body from client requests. I’ll get the Content-Type and Content-Lenght
in the request headers, but there’s no body after the headers. It does however forward the responses
correctly to client. In my case I was trying to implement an API and it kept failing because of
this issue.
Maybe I’m doing something wrong, if you have a solution do comment it below. You can read the full problem description in this discord thread
If you don’t have to do any of that and just serve basic html pages, then this’ll just work. Although, I asked around, and no one else faced an issue like this. Maybe I’m doing something wrong.